The Automated Forecaster
By Geoff ·
Every organization runs on predictions. A retailer deciding how many winter coats to order in July. An energy trader pricing next week's natural gas contracts. A newspaper editor deciding which stories to invest in before tomorrow's print deadline. A city planner modeling traffic flow for a bridge that won't be built for five years.
These are all forecasting problems. Today, most of them are solved poorly.
The state of forecasting in 2026
Here's how forecasting typically works at a large enterprise: a team of analysts pulls data from a warehouse, loads it into Excel or a BI tool, fits some statistical models (maybe ARIMA, maybe exponential smoothing), layers on judgment calls, emails the results to decision-makers, and repeats the process next week.
In most places, this workflow has barely changed in 30 years. And it breaks down in predictable ways:
- It doesn't scale. A human forecaster can maintain forecasts for maybe a few hundred time series with care. A large retailer has millions of SKU-store-day combinations to forecast every week.
- It ignores available information. The analyst knows that a Taylor Swift concert is coming to town and foot traffic will spike. But encoding that knowledge systematically, across thousands of locations, for every possible event? Good luck doing this in Excel.
- It's disconnected from decisions. The forecast says "we'll sell 10,000 units." But the real question is: "How many should we order, given our warehouse capacity, shipping lead times, and budget constraints?" The gap between forecast and decision is where most value is lost.
What a complete forecasting system actually requires
When we talk to enterprise customers, we find that the forecasting problem is never just a modeling problem. It is a system problem with at least four layers:
1. The right information
To forecast shoe sales, you need more than historical sales data. You need to know about fashion trends, influencer campaigns, competitor pricing, weather patterns, and upcoming holidays. Some of this information is in your data warehouse. Some of it is on social media. Some of it is on Apple's website (when is the next iPhone launch that will shift consumer spending?).
A human forecaster knows to search for this context. An automated system must do the same — systematically, at scale, and in real time.
2. Understanding the physics
Every time series has underlying dynamics. Restaurant foot traffic follows meal times and weather. Electricity demand follows temperature, daylight hours, and industrial schedules. Shoe sales follow fashion cycles, seasonal patterns, and macroeconomic conditions.
3. The model
This is where most of the research community focuses, and for good reason. The last few years have seen a revolution in forecasting models, from classical statistics to deep learning to foundation models — large pretrained models that have learned the dynamics of millions of time series and can generalize to new ones zero-shot.
We're building our own foundation model at the core of our system. But the model is just one component. Just as GPT-4 became dramatically more useful once it could search the web and execute code, a forecasting foundation model becomes dramatically more useful when embedded in a larger system.
4. The decision layer
"We'll sell between 10,000 and 11,000 units" is useful, but "you should order 8,500 units now, shipping from Warehouse B, to arrive by March 15" is actionable. The decision layer translates probabilistic forecasts into concrete recommendations, subject to real-world constraints: budgets, capacity, lead times, contractual obligations — that optimize your KPIs: service levels, cash flow.
This is where forecasting meets business metrics meets operations research, and it's where our forecasts create the most value for our customers. Today, we focus on the forecasting layer. Tomorrow, we will provide decision recommendations.
Our vision: the automated forecaster
Think about what an expert human forecaster actually does. They usually don't just run an ARIMA model. They:
- Explore the data — understand the structure, spot anomalies, identify patterns
- Search for context — look up events, trends, external factors that might affect the forecast, and explain where forecasts went wrong in the past
- Choose the right approach — select models, features, and parameters appropriate for the problem
- Generate forecasts — produce probabilistic predictions at multiple horizons and aggregation levels
- Validate and refine — check if the forecasts make sense, backtest against history, iterate
- Make recommendations — translate forecasts into decisions, accounting for business constraints
Our goal is to automate this entire workflow. We don't replace human judgment: we are giving our customers a system that does what the best human forecasters do — at the scale of millions of time series, updated continuously, with access to far more information than any individual could process.
We call this the automated forecaster.
The architecture
At the core is a proprietary time series foundation model — a transformer model pretrained on hundreds of millions of diverse time series. Unlike most existing foundation models, which are univariate (they see one series at a time), ours is designed to be multivariate and eventually multimodal. It can leverage relationships between series, incorporate external covariates, and process contextual information like text and categorical metadata.
We are building an agentic harness around the model. This is a system of AI agents that can:
- Search for relevant external information (macroeconomic data, event calendars, news, social media trends)
- Query the customer's own data warehouse for related series and covariates
- Perform temporal joins — aligning data sources with different frequencies, time zones, and measurement conventions
- Run backtests and evaluate forecast quality
- Detect when forecasts need to be refreshed or when the underlying dynamics have shifted
We evaluate rigorously — not just on public benchmarks like GIFT-Eval or fev-bench, but also every time we start a commercial discussion. We benchmark against every major foundation model and statistical baseline under a single standardized API. Customer trust underlies everything we do. This is how we prove to customers, with evidence, that our system works on their data.
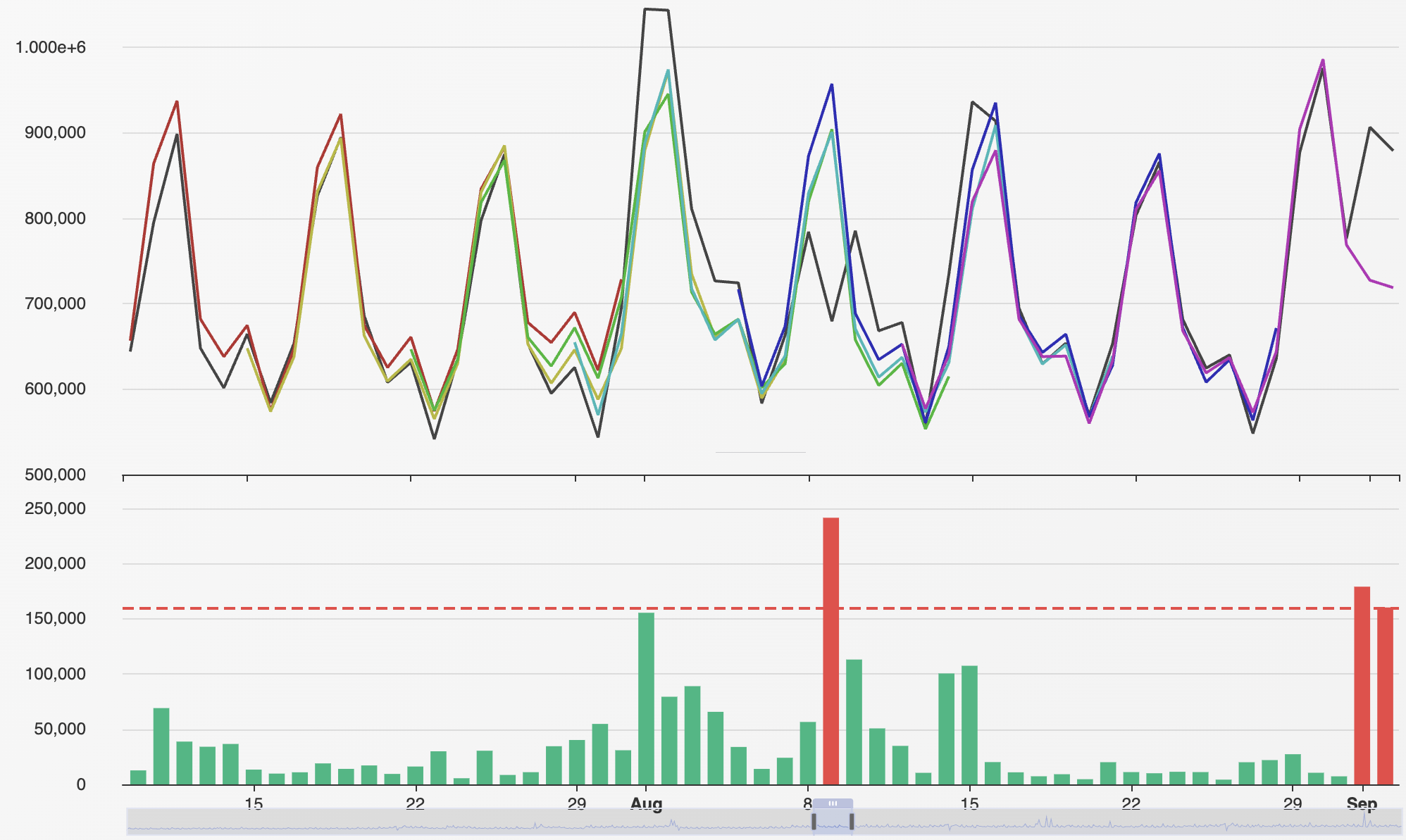
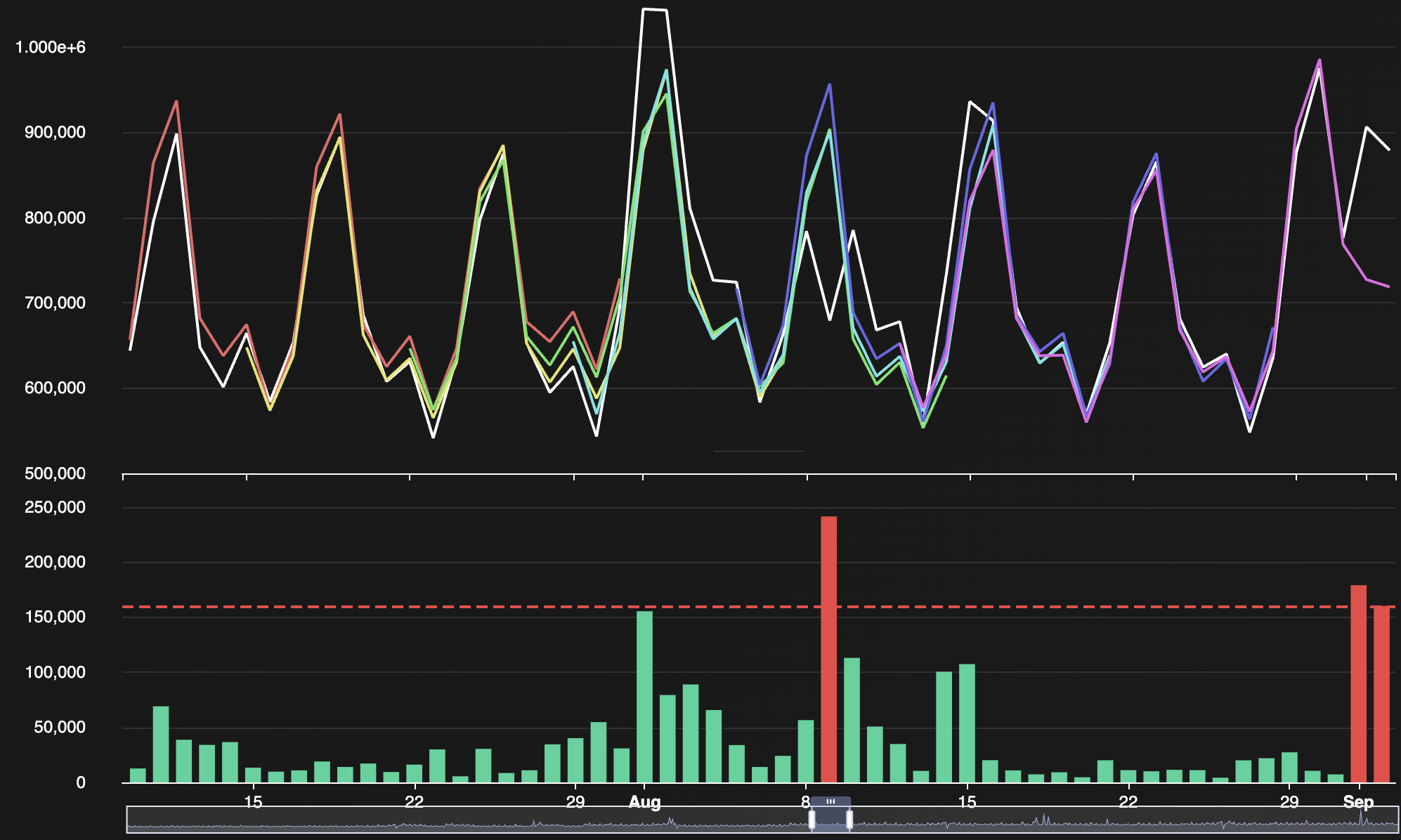
Around the harness is an API — a clean programmatic interface that lets the entire system be embedded anywhere. And around the API, multiple interfaces:
- An SDK for data scientists who want programmatic access
- A graphical interface, Retrocast, for business users who want to explore forecasts, add context, and build trust in the system
- Soon, fully agentic workflows where AI agents operate semi-autonomously on specific business problems — inventory management, energy trading, pricing optimization — with human oversight
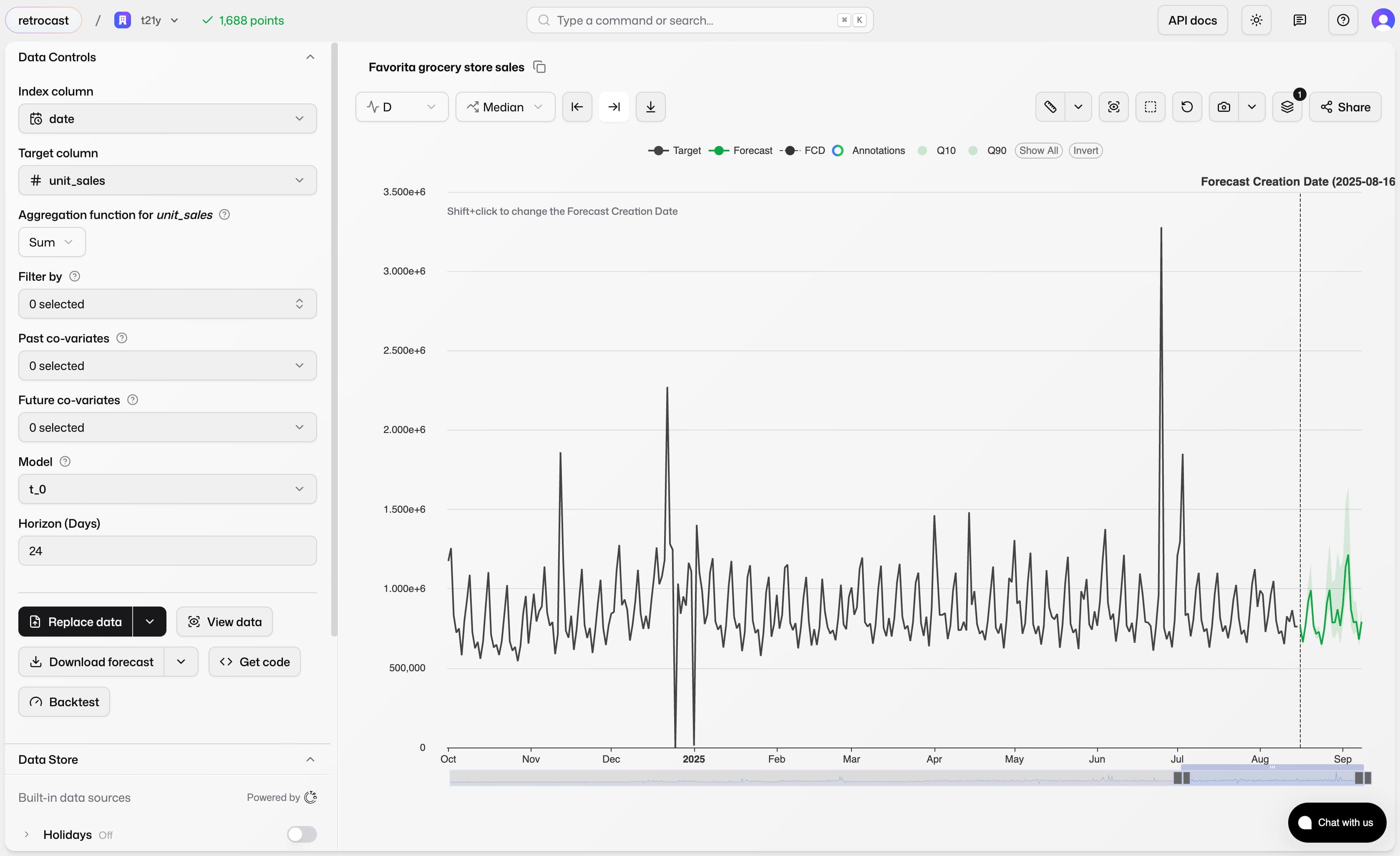
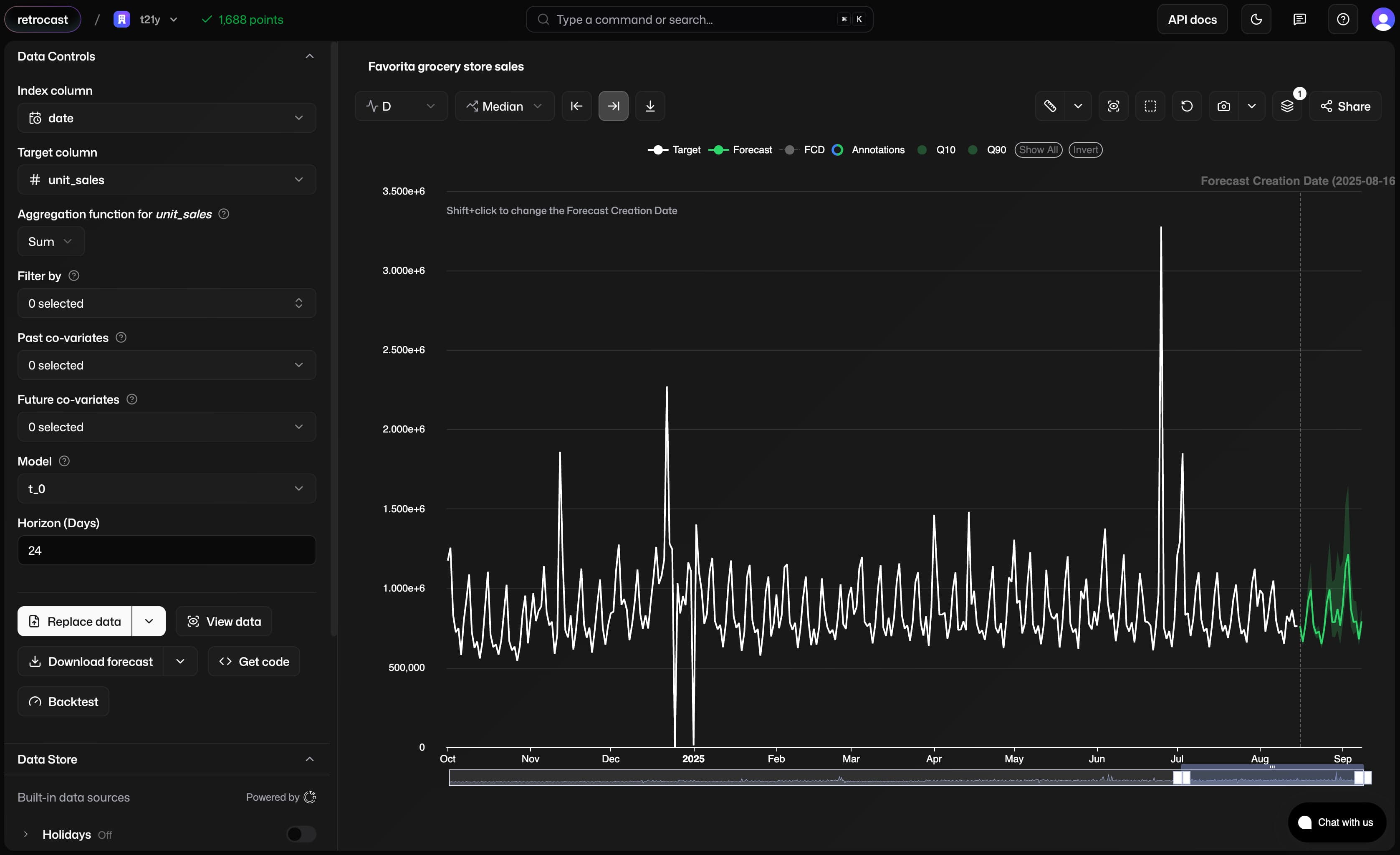
Why now?
The dream we describe is not new. In recent years, three things have converged to make it finally reality.
Foundation models work
LLM-powered agents are maturing
The same agentic frameworks that let ChatGPT browse the web and write code can be adapted for domain-specific forecasting tasks: searching for relevant data, performing temporal reasoning, validating outputs.
Enterprises are drowning in time series data
IoT sensors, digital transactions, supply chain telemetry — the volume of temporal data is growing exponentially, but the tools to make sense of it haven't kept pace.
Who we are
We are The Forecasting Company — an applied AI research lab focused exclusively on temporal data.
Our team comes from the institutions where large-scale forecasting was pioneered: Amazon (where transformer-based demand forecasting has been in production since 2019), Bloomberg and JPMorgan (where probabilistic models drive trillion-dollar trading decisions), Google (where foundation models are being scaled to time series), and Polymathic AI (where physics-informed machine learning meets scientific simulation). We are multinational from day one — built across the US and Europe, with the deep mathematical and engineering backgrounds that this problem demands.
We believe that temporal data deserves a dedicated research lab. The mathematics of time — calendar irregularity, hierarchical coherence, information availability, causal structure — is rich enough and hard enough that it rewards full-time focus. General-purpose AI labs treat time series as "just another sequence, or table." We know it isn't, and we're building the systems that prove it.
Our ambition is the all-purpose forecasting and temporal data platform: from data abstractions, to modeling, to search, to decisions. The end goal is to put companies on autopilot with good decision recommendations — starting at the operational level, then expanding to strategic planning.